近日,计算机与信息学院PRiSE(Pattern Recognition and Intelligence Software Engineering)研究团队23级硕士研究生吴童在人工智能与软计算领域国际期刊《Applied Soft Computing》(中科院二区TOP)发表题为“Tensor idempotent representation with auto-weighted exponential tensor nuclear norm minimization for multi-view clustering”的研究成果,安徽工程大学为论文第一署名单位。
针对现有多视图聚类方法难以获得清晰张量块对角结构、张量核范数约束容易过度收缩较大奇异值并造成关键信息损失等问题,该论文提出了基于自加权指数张量核范数最小化的张量幂等表示多视图聚类方法(TIR/AWETNN)。该方法首先利用原始样本矩阵的自表达特性学习各视图自表达矩阵,并将其堆叠为张量;随后设计张量幂等表示以获得更加清晰的张量块对角结构,从而充分利用多视图之间的一致性信息并增强算法鲁棒性。在此基础上,论文提出自加权指数张量核范数作为张量秩的更优替代约束,通过非凸惩罚函数区分不同奇异值的物理意义,更准确地刻画多视图高阶相关性。最后,论文采用增广拉格朗日乘子法将上述过程统一到同一优化框架中。多个数据集上的实验结果表明,该算法相比现有先进方法具有更优聚类性能,部分数据集性能提升最高可达42.78%。
研究主要创新点:1.提出了一种新的张量幂等表示多视图聚类方法,通过自表达矩阵构建表示张量并获得清晰的张量块对角结构,进一步提升了多视图一致性信息的利用效率和算法鲁棒性;2.设计了自加权指数张量核范数约束,利用非凸惩罚函数充分考虑不同奇异值的物理差异,有效缓解传统张量核范数对较大奇异值过度收缩的问题,更准确地刻画多视图数据的高阶相关性;3.将自表达学习、张量幂等表示和低秩张量学习统一到同一优化框架中,并在多个公开数据集上验证了方法的有效性。
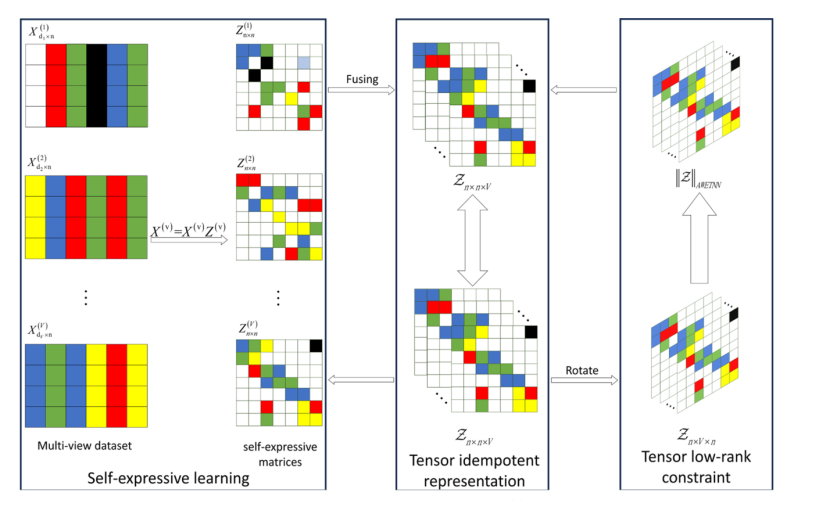
图1 TIR/AWETNN 方法总体流程图。该方法由自表达学习、张量幂等表示和张量低秩约束三部分组成。
论文原文链接:https://doi.org/10.1016/j.asoc.2025.113103